|
I am an AI researcher with prior research experience in research on building computational models of perceptions in 3D inspired by cognitive science to endow future AI agents with visual intelligence. I am lucky to be an affiliate of CoCoSci and CNCL. I was fortunate to be a research assistant at Josh Tenenbaum's Computational Cognitive Science Lab at Massachusetts Institute of Technology. I graduated in 2016 with a Master's Degree in Computer Science from State University of New York at Buffalo. Prior to that, I did my undergraduate at Isalamic Azad University in Iran, where I received my B.S. in Computer Software Engineering. Email / Google Scholar / GitHub / LinkedIn / Twitter |

|
|
My long-term research goal is to enable AI agents to have the ability to imagine (produce mental or abstract imagery without sensory inputs) by building models of the visual world and come up with concise and generalizable theories/solutions that can explain phenomena beyond what low-level statistics of observable data spells. |
|
|
|

|
|

|
Inspired by the idea of vision as inverse graphics, we propose a Bayesian model for face recognition that achieves both human-level and somewhat human-like performance on stimuli that humans do not have expure to normally |
|
This work is a contribution towards The Core Object System. Here, we show that preschool children are able to use their "intuitive" physical knowledge of how cloths work and reason about what shape has been draped by cloth, hence uncovering the true object. |
|
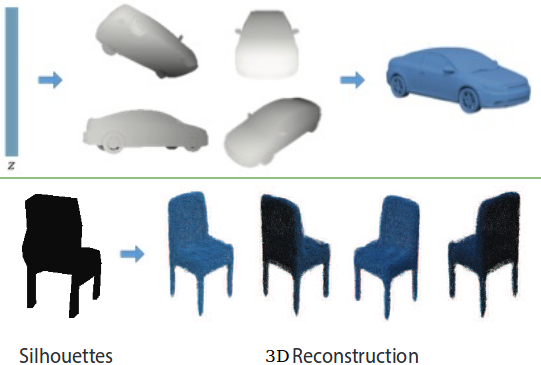
Soltani, AA., Huang, H., Wu, J., Kulkarni, T., & Tenenbaum, J. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017 Paper (PDF) / Code / Poster / Slides (includes more results) A generative model for generic 3D shapes to obtain abstract description of objects as a crucial component for building models of the environment through inverse graphics. |
|
|